
-
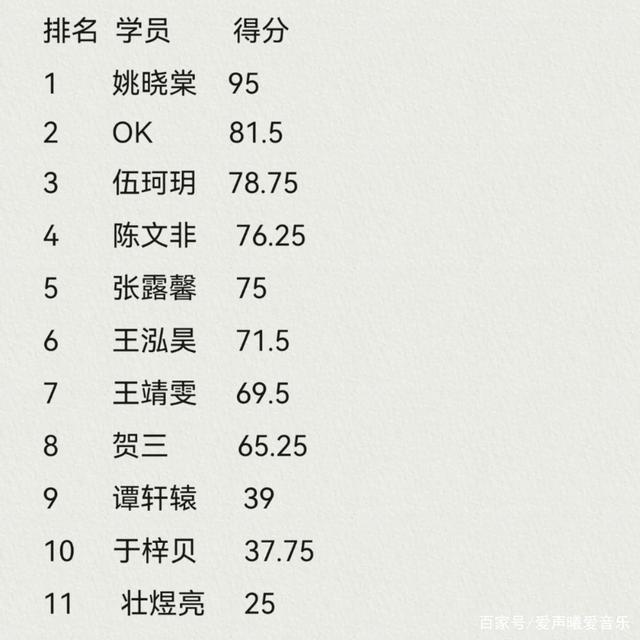
- 中国好声音第三季免费(中国好声音第三季免费下载)
-
《中国好声音2020》是由浙江卫视推出的音乐励志评论类节目,由谢霆锋、李健、李荣浩、李宇春担任固定导师,该节目坚持从音乐出发,为怀揣梦想的音乐人提供一个一展才华、实现梦想的舞台,用音乐为自己、为时代发声。中国好声音2020第四期抢先看,最激...
-
2025-12-21 21:54 alicucu
- 预防近视的小口诀(预防近视的小口诀是什么)
-
保护眼睛,预防近视因为过度使用电子设备、长时间注视屏幕、不足的户外活动等因素都会增加近视的风险,所以需要注意保护眼睛,预防近视的发生。口诀短句可以分为以下几个方面:1.多户外活动,眼保健操常做2....
- 电脑上门维修(电脑上门维修收费标准)
-
电脑城,一般来说虽然贵点,但是不会偷工减料(但也说不准)。街边的店面一般来说,你要知道他的口碑怎么样。还有,开店的时间是多长,一般来说,开店没多久的,他不会占你便宜,价格也是通俗的,该修好还是修好,不...
- 牛肉干(牛肉干怎么做家庭制作方法)
-
牛肉干是一种深受人们所欢迎的小零食,吃起来不仅有嚼劲,而且还有种唇齿留香的感觉。风味独特的牛肉干,既可以当做追剧时的小零食,又可以当做一种美味的下酒菜,无论是大人还是小孩都很喜欢吃。做法如下:食材与明...
- 二氧化碳与水反应(二氧化碳与水反应的实验)
-
二氧化碳和水反应属于化合反应,它是酸性氧化物与水反应生成酸,二氧化碳与水反应生成碳酸,这是一个可逆反应,碳酸受热后会析出二氧化碳气体。二氧化碳是一种碳氧化合物,化学式为CO2,化学式量为44.0095...
- 胆怯的反义词是什么(胆怯的反义词是什么啊)
-
反义词:勇敢无畏胆怯:胆小害怕:心虚胆怯。近义词:怯懦懦弱例句:1)这女孩胆量真大,在台上表演,落落大方,毫不胆怯。2)临上场的时候,她胆怯了,畏缩着不敢走上舞台。3)她初次走上讲台,还...
- 十大经典军事小说(军事小说经典之作)
-
楚汉争鼎强推大争之世强推五胡烽火录盗明强推大唐盗帅铁血大秦强推盗宋逐鹿夏鼎回到明朝当王爷回到唐朝当皇帝回到秦朝当皇子官居一品强推回到战国之我是嫽毐枕醉江山调教初唐1908大军阀强推大周皇族...
- 2025年高考预计录取分数线(2025年全国高考人数是多少)
-
2021年高考录取分数线为理科458分,文科为460分。每年的文科录取分数线比理科的录取分数线都要高。这主要是因为理科各科试题的难度比文科的试题的难度要大一点。而且全国范围内,文科的大学本来就少。所以...
- 经济学就业方向和前景(经济学就业前途)
-
就业方向:毕业后在各级政府管理部门、科研院所、高等院校、公司、企业等从事经营管理,经济管理,经济分析、预测和规划,政策分析等工作;还可进一步报考相关学科门类的博士研究生,继续求学深造。前景:经济学硕士...
- 恐怖之家2手机版下载(恐怖之家2在线玩)
-
关于这个问题,1.《死亡空间》(DeadSpace)这款游戏以恐怖的科幻风格为主题,讲述了宇宙船员在太空站上遭遇外星生物的故事。玩家需要在太空站上进行探索和战斗,并使用各种武器和工具来对抗外星生物。...

